
5 月 21 日,阿里巴巴发布新一代旗舰大模型 Qwen3.7-Max。官方资料显示其在 Artificial Analysis 评测中得分 56.6,对标 GPT-5.4,并提及“10 倍推理加速”。OmniTools 调研发现,这里的“加速”并非指 API 响应速度提升,而是该模型在无人类干预下连续运行 35 小时、执行 1158 次工具调用,自主优化出的推理内核比官方参考实现快了 10 倍。
从单轮对话生成转向长周期自主执行,Qwen3.7-Max 试图在 Agent 时代的生产力底座中占据核心位置。面对输出价格仅为 GPT-5.4 三分之一的定价,以及兼容 Claude Code 的生态策略,这款模型在实际开发工作流中究竟能省下多少成本?其长时运行能力又存在哪些限制?
能力水位与“10 倍加速”的实际含义
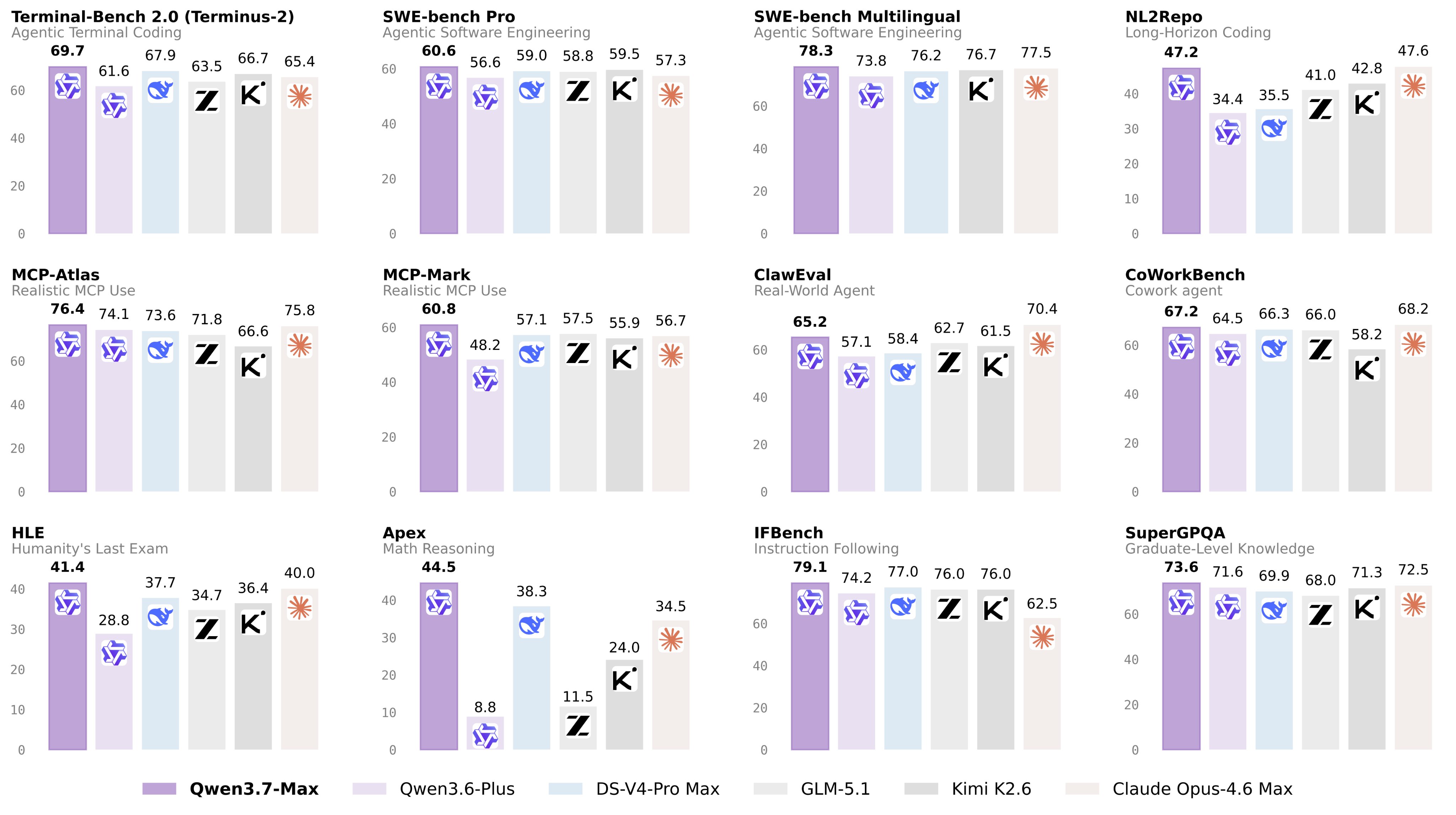
在评估大模型能力时,第三方独立评测通常比单一维度的跑分更具参考性。根据 Artificial Analysis Intelligence Index 数据,Qwen3.7-Max 综合得分为 56.6,位列全球第 5,较前代 Qwen3.6 Max Preview(51.8 分)有明显提升,与 GPT-5.4 (xhigh) 处于同一区间。
关于官方提及的“10 倍推理加速”,OmniTools 查阅相关技术细节后确认,这是一个 Agent 长时执行的展示案例。Qwen3.7-Max 在平头哥真武 M890 芯片上,自主运行 35 小时,执行 1158 次工具调用,编写并优化了一个生产级 AI 推理内核。最终该内核比 SGLang Triton 官方参考实现快了 10 倍。
这一案例反映了 Qwen3.7-Max 的产品定位:核心卖点在于长周期自主执行与系统级问题解决能力。在复杂的 Agent 工作流中,模型需要具备任务拆解、实时纠错和持续执行的能力。35 小时的连续运行展示了其在长上下文和长逻辑链下的稳定性。
不过,该能力的普适性存在前提条件。这一加速结果基于特定的自研芯片(真武 M890)和推理框架(SGLang Triton)。若开发者在 NVIDIA GPU 或其他主流框架上调用 API,能否获得同等的系统级优化效果,目前官方技术报告尚未披露具体细节。
Agent 经济账:输出成本与并发限制
对于企业客户和开发者,Agent 的规模化落地取决于投资回报率(ROI),API 定价是核心变量。
阿里云百炼官方数据显示,Qwen3.7-Max 的定价为:输入 12 元/百万 Token,输出 36 元/百万 Token,支持 1M 上下文窗口。作为对比,OpenAI GPT-5.4 在 OpenRouter 等平台的输出价格约为 15 美元/百万 Token(折合人民币约 108 元),Anthropic Claude Opus 4.6 的输出价格为 75 美元/百万 Token(折合人民币约 540 元)。
在 Agent 工作流中,由于涉及思考链(Thinking)、环境观察和工具调用结果,输出 Token 的消耗量通常远大于输入 Token。Qwen3.7-Max 的输出价格约为 GPT-5.4 的三分之一,不到 Opus 4.6 的十分之一。假设一个企业级代码审查 Agent 每天产生 1000 万输出 Token,使用 Qwen3.7-Max 的日成本约为 360 元,而使用 Opus 4.6 则超过 5000 元。这种成本差异直接影响长时运行 Agent 的商业可行性。
此外,阿里云百炼为 Qwen3.7-Max 设定的默认并发限制为 RPM(每分钟请求数)30,000,TPM(每分钟 Token 数)5,000,000。这为企业级高并发 Agent 集群提供了基础支持,降低业务高峰期因限流导致任务中断的概率。
生态兼容:替换 Claude Code 底座的迁移成本
在开发者生态方面,Qwen3.7-Max 采取了针对性的兼容策略。阿里云百炼官方文档提供了 Claude Code 的接入指南,允许开发者通过配置 API 端点,将 Claude Code 默认的 Opus 模型替换为 qwen3.7-max。同时,Agent 开发框架 OpenClaw 也将 Qwen 列为内置提供商。
这种兼容是工具链层面的平替。Claude Code 作为终端 AI 编程工具,其工作流和快捷键已形成用户习惯。通过端点替换,开发者无需修改本地的 Agent 工作流,只需更改环境变量,即可将底层模型切换为 Qwen3.7-Max。这降低了开发者的迁移门槛。
需要注意的是,百炼文档中提示“Coding Plan 不支持”。这意味着开发者可能无法使用 Anthropic 官方的包月订阅套餐,而必须通过阿里云百炼按量付费。对于高频使用的个人开发者,按量付费在特定使用强度下的成本可能会超过包月订阅,工具选型时需根据实际代码产出量进行测算。
竞品横评:全球与国产旗舰中的差异化路线
将 Qwen3.7-Max 置于当前旗舰模型坐标系中,可以看到其差异化的技术路线。
对比 GPT-5.4:在 Artificial Analysis 综合指数上两者接近。但在技术路线上,GPT-5.4 侧重原生的 Computer Use(屏幕 GUI 操控)能力;Qwen3.7-Max 则侧重 MCP(Model Context Protocol)协议与长时代码优化,倾向于通过 API 和代码级工具链解决工程问题。
对比 Claude Opus 4.6/4.7:在 MCP-Atlas 评测中,Qwen3.7-Max 取得 76.4 分,与 Opus 系列表现接近。结合其输出成本优势,Qwen3.7-Max 为企业提供了一个兼顾能力与成本的替代方案。
对比国产模型:在 Agent 专项评测 MCP-Mark 中,Qwen3.7-Max 得分 60.8,高于 GLM-5.1 的 57.5 分。在工具调用和复杂指令遵循能力上,Qwen3.7-Max 在国内模型中处于领先位置。
限制与暗礁:闭源策略与长时运行的风控
尽管在能力和价格上具备优势,Qwen3.7-Max 在实际落地中仍面临一些限制。
首先是闭源策略带来的影响。Hacker News 上有开发者指出,Qwen3.7-Max 作为闭源专有模型,与 Qwen 系列以往的开源策略有所不同。OmniTools 分析认为,旗舰模型闭源、中小模型开源是当前厂商维持商业竞争的常见做法,但这确实限制了部分依赖本地私有化部署和模型微调的开发者使用,在对数据隐私要求极高的离线场景中适用性降低。
其次是长时运行带来的成本失控风险。Agent 长时执行的痛点在于“幻觉累积”和“死循环”。官方展示了 35 小时成功运行的案例,但未披露该测试的失败率。如果 Agent 在复杂任务中陷入逻辑死循环,不断重复调用工具并生成无效思考链,Token 消耗量将快速上升。目前,官方文档尚未明确说明 API 层面是否原生提供针对 Agent 死循环的“单次运行 Token 上限”或“异常调用自动熔断”机制。企业客户在生产环境中部署时,需要在应用层自行设计“人类介入(Human-in-the-loop)”的兜底方案与成本监控报警系统。
总结
Qwen3.7-Max 的发布,反映了国产大模型在 Agent 领域的竞争重点正转向长时执行可靠性与商业落地成本。它以对标 GPT-5.4 的综合评测表现、较低的输出 Token 价格以及对主流开发框架的兼容,为企业级 Agent 部署提供了一个选项。
但在工具选型时,特定硬件下的加速红利能否泛化、长时运行中的 Token 熔断机制是否完善,以及闭源策略对私有化部署的限制,都是开发者和企业在接入前需要评估的现实问题。Agent 基础设施的竞争仍在继续,Qwen3.7-Max 的实际市场表现,将由开发者的真实调用数据和账单来验证。